



Romley@Xeon E5 英特尔“云端”利器
实测二 存储I/O喜忧参半
之前我们说到C600整合了8端口SAS 3Gb/s,这是英特尔的一次尝试。其实际效果如何呢?《微型计算机》评测室和ZDNet评测中心一起验证了英特尔在SAS上的实力。8个SAS 3Gb/s接口,理论上能提供约2GB/s的I/O速度。虽然搭配8个类似Intel 520这样的SSD肯定会遇到瓶颈。但若尽可能提高传输效率,让实际带宽逼近2GB/s。

板载的2个SAS 3Gb/s接口,皆为单接口4端口设计,共计8个SAS端口。
那么这个板载的SAS控制器还是能很好地满足HDD RAID的需求,为不需要高性能SSD RAID的Romley平台用户省下一笔存储卡扩展支出。作为对比,我们准备了提供8个SAS 6Gb/s 端口的LSI SAS 9211-8i HBA扩展卡。

8×SSD的待测存储系统。请注意,为了减少RAID层延时对大I/O性能的影响,我们并没有组建任何RAID,而是直接测试8×SSD情况时的系统吞吐能力。
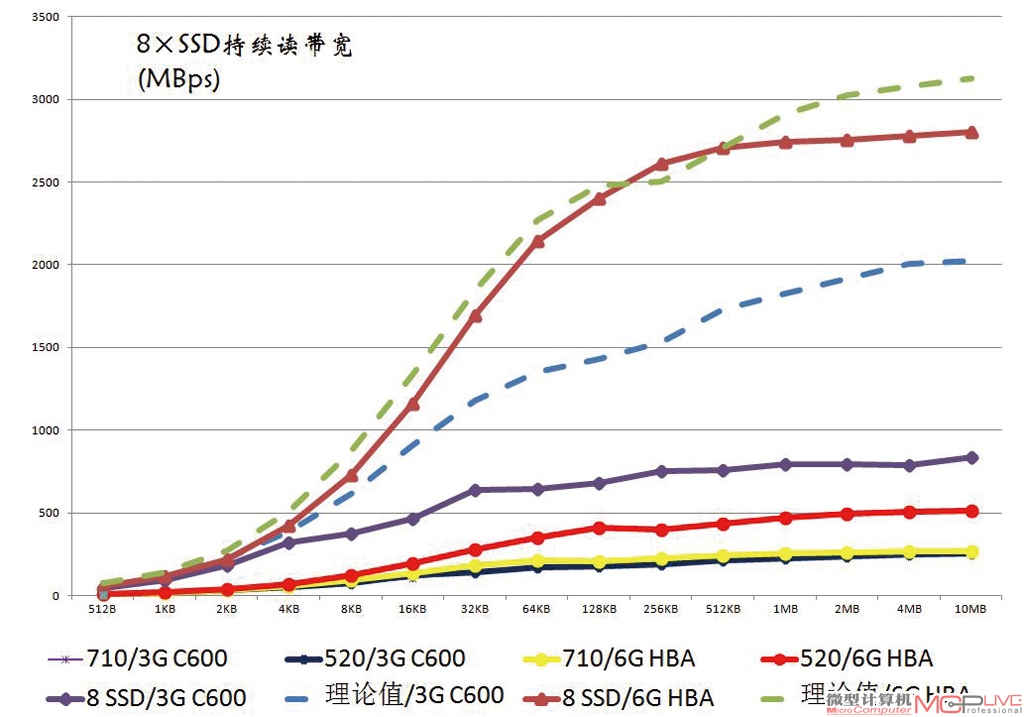
要想榨取接口的性能极限,就需要足够高的数据传输率。我们准备了4×Intel 520加4×Intel 710共计8个SSD的配置。测试开始时,我们先在Intel C600芯片集成的3Gb/s SAS端口和LSI SAS 9211-8i HBA集成的6Gb/s SAS端口下,对单个Intel 710和Intel 520的持续读取能力进行了测试,并据此估算出8个SSD并发读取时的理论值。限于DMI 2.0总线实际传输速度只有4×PCI-E 2.0,约1.8GB/s。因此,我们8×SSD组合2.02GB/s的理论速率是完全能喂饱这个板载SAS的。

主板上的专用I/O接口,用来连接Intel RMS25CB080模块。其核心是一颗LSI SAS2208芯片。它是早支持PCI-E 3.0标准的6Gb/s SAS控制器,SAS端口数量也是8个。
终测试结果让我们颇感意外,原本我们以为C600集成的8×3Gb/s SAS能获得接近1.8GB/s的传输性能,实际上限却仅能到达900MB/s。这样的数据传输性能可能连高性能的8×HDD都满足不了。而LSI SAS 9211-8i HBA的表现则相当优秀。基本上和理论I/O值相吻合,高速率达到了2.8GB/s。

RMS25CB080模块下,2×Intel 520 SSD RAID 0测试成绩。
可能正是考虑到C600集成的SAS性能水平有限,英特尔为送测的Server System R2000系统搭配了一款型号为Intel RMS25CB080的集成RAID模块。这个模块理论上能为我们带来8GB/s的大I/O性能,鉴于我们还没有能对它造成压力的I/O系统。所以我们只简单测试了用它组建两块Intel 520 SSD RAID 0的效率。测试结果相当满意,这个RAID的性能基本上接近了单个Intel 520性能的两倍。
| Intel 520/710SSD数据传输能力实测数据表 | ||
| 顺序读(MB/s) | C600 3Gb/s SAS | 6Gb/s SAS HBA |
| SSD 710 | 253 | 266 |
| SSD 520 | 252 | 514 |
| 4×(710+520) | 2020 | 3120 |
实测三 网络I/O提升10倍
在这里不得不说一下,送测的平台并没有随机配备SFP+光纤模块,所以用户不论以什么途径提供光纤模块都将增加每端口成本,算下来将是笔不小的开支。针对此,我们认为:要想让万兆网络迅速普及开来,先得让相对廉价且易用的10GBase-T Cat-6/6a标准成为市场主流。
想在评测室中体验万兆网络并不容易,为此我们设计了2台Server System R2000服务器互联,通过虚拟机迁移来体验网络性能的测试方案。并分别对比了两服务器间用万兆端口和双千兆端口迁移的性能。我们创建了分配有64GB内存的虚拟机蓝本,并克隆了8个。将它们全部放在一台Server System R2000服务器上,全部开机。由于测试平台内存总容量的限制,每个虚拟机实际占用的内存约为12GB。随后,我们以1、4、8为单位向另一台Server System R2000服务器上迁移。来回各一次,记录迁移时间。
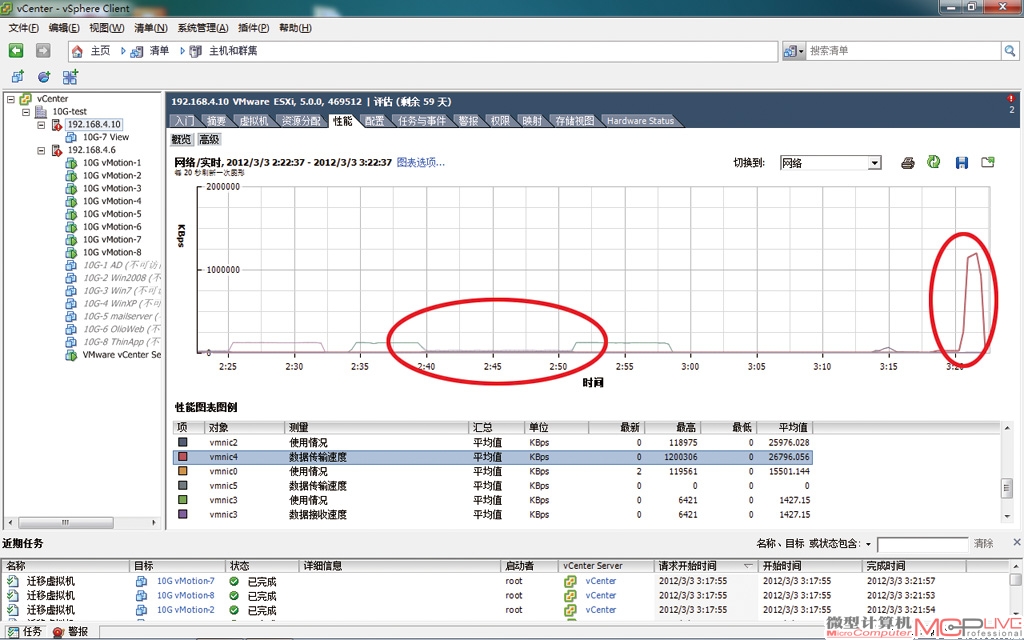
与千兆网络(vmnic2,接近120MB/s)峰值速率的对比,正好是10倍的差距。两个红色椭圆框的对比则更直观,左侧是千兆网络迁移的状况,可以看到分两批迁移(每批4个VM),中间的停顿比较长;右侧的万兆网络迁移时间(横轴)短很多,纵轴(传输率)则相当高。")
红色方框内显示了万兆网络(vmnic4,1.2GB/s)与千兆网络(vmnic2,接近120MB/s)峰值速率的对比,正好是10倍的差距。两个红色椭圆框的对比则更直观,左侧是千兆网络迁移的状况,可以看到分两批迁移(每批4个VM),中间的停顿比较长;右侧的万兆网络迁移时间(横轴)短很多,纵轴(传输率)则相当高。
对比的结果比较有趣。在同时迁移的虚拟机数量较少的时候(1个和4个),双千兆网络所用的时间不到万兆网络的5倍。由此看,万兆网络的效率貌似不高。其实这只是因为迁移开始前,系统需要进行一些预处理(在本地做一些运算和处理)。这段时间vMotion网络上流量甚少,万兆网络和千兆网络没有什么区别,消耗的时间差不多,随后迁移才正式开始。由于之前用掉了一些时间做预处理,所以万兆网络5倍的带宽优势就被抵消了一些。

双路至强E5 2690、X5680功耗对比。新系统优秀的性能并没有以增加功耗为前提,相反的,至强E5 2690系统的功耗表现还全面优于老系统。
但当同时迁移的虚拟机数量提升到8个时,双千兆网络所用的时间又超过了万兆网络的5倍,甚至接近6倍。这又是为什么呢?仔细观察迁移曲线图(左上),你会发现:在双千兆网络上,由于高带宽的限制,vMotion没有同时启动8个虚拟机的迁移,而是分成两批。每次预处理的只有4个虚拟机信息。在第一批迁移接近完成,第二批迁移将要启动的时候,“交接”的时间相对较长,导致总用时比依旧一次预处理8个交换机信息的万兆网络要长得多。
| 万兆和双千兆网络迁移虚拟机耗时对比表 | ||
| vMotion数量 | 2×1Gb网络耗时 | 10Gb网络耗时 |
| 1 | 129s | 30s |
| 4 | 460s | 111s |
| 8 | 1449s | 246s |
当然,面对并不成熟的万兆网络应用环境,我们的体验和测试只能算是浅尝辄止。但这也足够展示出万兆网络相比当前千兆网络的性能优势。后续我们将为大家带来更多的万兆网应用指南和性能测试,用户们尽情期待吧。
Romley——没有瓶颈的云端立交,只欠互联高速
Romley平台不论是计算性能还是I/O性能上的表现都极为出色,相比上代产品甚至有翻番的提升。特别是万兆网络的一次载入优势和高持续传输能力,让人映像深刻。如果说未来的云计算环境就是一个错综复杂的数据交通网络,那么大大小小的服务器就是一个个重要的云端立交。现在,Romley平台已经将更先进的立交架构带到我们面前,也带来了新的万兆高速连接方案。剩下的就是等待10GBaet-T的快速普及,并期待未来更加顺畅和精彩的云应用!
LRDIMM内存的引入,让E5 2600系列能提供了至强X5600系列2.6倍的内存支持能力。新平台对虚拟化市场的促进无疑会相当明显。
从对比上我们可以看出,至强E5 2690相比上一代的X5680来说各方面都进步明显。更快速的相应时间、更强大的性能和更低的功耗是我们希望看到的,而英特尔的确给了我们这些新的惊喜。
MC点评:在我们的测试中,以至强E5处理器为核心的Romley平台表现相当出色。相比至强X5500系列,它在计算性能、I/O、内存性能、存储性能和功耗控制等各方面都体现出了“换代”的绝对优势。事实上,凭借在网络和存储上的技术创新,Romley平台无疑会成为云计算时代企业用户的绝佳选择,担负起英特尔期望中的“未来服务器平台中流砥柱”的使命应该不成问题。


{kind=link}
{kind=link}